Follow set of a given grammar using Array in Compiler Construction
Syntax analysis is the second phase of a compiler. The lexical analyzer works closely with the syntax analyzer. It reads character streams from the source code, checks for legal tokens, and passes the data to the syntax analyzer for further processing. Follow set in parsing is the continuation of first set.
This lecture teaches you
- How to find the tokens/variables that are the ending symbols of a grammar
Students should know how to write a program for finding the first set of grammar rules in C#
Introduction
FOLLOW covers the possibility that the leftmost non-terminal can disappear, so that the lookahead symbol is not actually a part of what we’re presently expanding, but rather the beginning of the next construct.
Consider parsing the string ‘ab’, which starts us off at (‘S’,’ab’). The first decision comes from FIRST(S) again, and goes through (‘aAb’,’ab’), to (‘Ab’,’b’).
In this situation, we need the A to vanish; although A can not directly match ‘b’, ‘b’ can follow A: FOLLOW(A) = {b} because b is found immediately to the right of A in the result of the first production, and A can produce the empty string.
A -> <epsilon> can’t be chosen whenever strings begin with <epsilon>, because all strings do. It can, however, be chosen as a consequence of noticing that we need A to go away before we can make further progress. Hence, seeing (‘Ab’,’b’), the A -> <epsilon> production yields (‘b’,’b’), and success in the next step.
This is the significance of the FOLLOW sets: they tell you when a non-terminal can hand you the lookahead symbol at the beginning of a statement by disappearing. Choosing productions that give <epsilon> doesn’t reduce the input string, but you still have to make a rule for when the parser needs to take them, and the appropriate conditions are found from the FOLLOW set of the troublesome non-terminal.
Both Top-Down and Bottom-Up Parsers make use of FIRST and FOLLOW for the production of Parse Tree from a grammar. In top down parsing, FIRST and FOLLOW is used to choose which among the grammar is to apply, based on the next input symbol (lookhead terminals) in the given string. During panic-mode error recovery, sets of tokens produced by FOLLOW can be used as synchronizing tokens.
FIRST(S), where S is any string of grammar symbols is the set of terminals that begin strings derived from a. If S =>* a, then a will be added among FIRST (S).
Define FOLLOW(S) for nonterminal S, to be the set of terminals a that can appear immediately to the right of A in some sentential form; that is, the set of terminals a such that there exists a derivation of the form S =>* aAa. There may have been symbols between S and a, at some time during the derivation, but if so, they derive ɛ and disappeared. A can also be the rightmost symbol in some sentential form, then $ is in FOLLOW(A), where $ is a special “end marker” symbol that is not to be a symbol of any grammar.
They are also used for error recovery. As you want a compiler to find the maximum of errors in your program, when it finds an error, it skip the symbols until it finds one which is in the possible follower. It will not correct the program, but the compiler will resume checking syntax as soon as possible.
Follow set are all what can follow a given symbol. For example after the symbol “+” you can have a number (thus a digit), an identifier (thus a letter) or a parenthesis (thus “(“).
Lab Activities:
Activity 1:
Write a program that takes at least six grammar rules. Based on these rules and after calculating the first of all the non-terminals, find the follow sets of these variables.
Solution:
C Program To Find Follow of a Grammar using Array
#include<stdio.h>
#include<ctype.h>
#include<string.h>
int limit, x = 0;
char production[10][10], array[10];
void find_first(char ch);
void find_follow(char ch);
void Array_Manipulation(char ch);
int main()
{
int count;
char option, ch;
printf(“\nEnter Total Number of Productions:\t”);
scanf(“%d”, &limit);
for(count = 0; count < limit; count++)
{
printf(“\nValue of Production Number [%d]:\t”, count + 1);
scanf(“%s”, production[count]);
}
do
{
x = 0;
printf(“\nEnter production Value to Find Follow:\t”);
scanf(” %c”, &ch);
find_follow(ch);
printf(“\nFollow Value of %c:\t{ “, ch);
for(count = 0; count < x; count++)
{
printf(“%c “, array[count]);
}
printf(“}\n”);
printf(“To Continue, Press Y:\t”);
scanf(” %c”, &option);
}while(option == ‘y’ || option == ‘Y’);
return 0;
}
void find_follow(char ch)
{
int i, j;
int length = strlen(production[i]);
if(production[0][0] == ch)
{
Array_Manipulation(‘$’);
}
for(i = 0; i < limit; i++)
{
for(j = 2; j < length; j++)
{
if(production[i][j] == ch)
{
if(production[i][j + 1] != ‘\0’)
{
find_first(production[i][j + 1]);
}
if(production[i][j + 1] == ‘\0’ && ch != production[i][0])
{
find_follow(production[i][0]);
}
}
}
}
}
void find_first(char ch)
{
int i, k; if(!(isupper(ch)))
{
Array_Manipulation(ch);
}
for(k = 0; k < limit; k++)
{
if(production[k][0] == ch)
{
if(production[k][2] == ‘$’)
{
find_follow(production[i][0]);
}
else if(islower(production[k][2]))
{
}
else
{
}
}
}
}
Array_Manipulation(production[k][2]);
find_first(production[k][2]);
void Array_Manipulation(char ch)
{
int count;
for(count = 0; count <= x; count++)
{
if(array[count] == ch)
{
return;
}
}
array[x++] = ch;
}
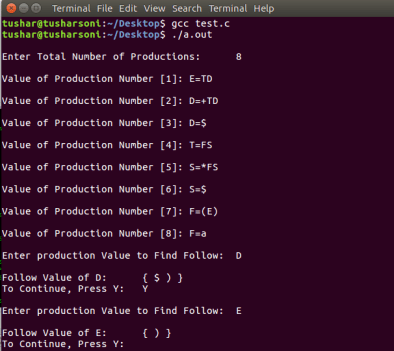
Output:
Home Activities:
Activity 1:
Write a code for the grammar with at least 10 non-terminals.
Assignment:
Students must submit their home task before next lab with good understanding.
Related Links
- Introduction to C#
- Lexical Analyzer Recognition of operators/variables
- Recognition of keywords/constants
- Lexical Analyzer Input Buffering scheme
- Symbol Table in Compiler Construction
- First set of a given grammar using Array
- Follow set of a given grammar using Array
- Bottom-up Parser-I DFA Implementation
- Bottom-up Parser-II Stack parser using SLR
- Semantic Analyzer
#Compiler Construction complete course # Compiler Construction past paper # Compiler Construction project #Computer Science all courses #University Past Paper #Programming language #Introduction to C# #Lexical Analyzer Recognition of operators/variables #Recognition of keywords/constants #Lexical Analyzer Input Buffering scheme #Symbol Table in Compiler Construction #First set of a given grammar using Array #Follow set of a given grammar using Array #Bottom-up Parser-I DFA Implementation #Bottom-up Parser-II Stack parser using SLR #Semantic Analyzer